Improved Keyword Density

I’ve heard recently that keyword density is obsolete and should no longer be a factor in SEO. I want to get to the bottom of this issue in this post, and describe the new improvement to our software’s keyword density feature.
First of all, let’s start by explaining what keyword density is. Search engines are automatic processes that have to parse web pages for their content to figure out what a page is all about. There simply is no better way a software can figure out what is the content of the page without parsing the content. They can figure out something by looking at the links to that page, but that is very limited. So, this means that Google and the other search engines must parse our web pages to figure out what our content is about, and the most obvious way would be to simply take the content of the web page, clean all the html code, js, css and just stay with the content that the user is seeing on the screen. Then, count how many times each keyword appears, and maintain that list and use it to categorise the web page. Here is how this looks like for our home page:
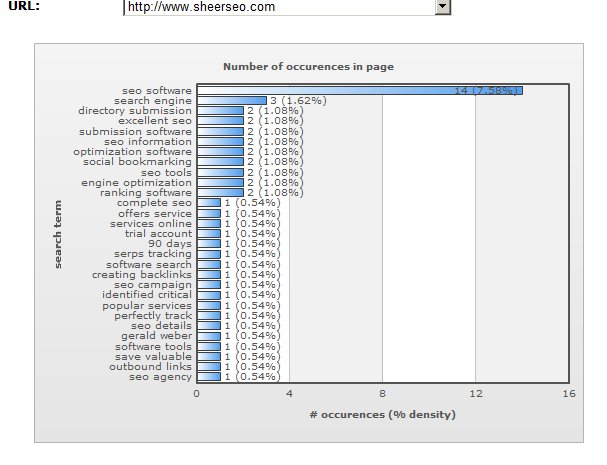
So, a search engine looking into this page, knows “seo software” is what this page is focused on.
To compare this page to others, it isn’t enough just to count the words, cause that would mean you won’t be able to compare this page with short ones. So, search engines need to look at the percentage of the keyword in the overall count of words in the page. And the final formula for keyword density is: (number of times the keyword appears)*(number of words in the keyword)*100/(number of keywords in the page).
The first improvement we did now in our SEO software is to add the percentage of each keyword, and not just the count as was before. BTW, people say that more than 9% density would be considered as spam. This makes sense.
Now, this is how Google probably done this in the early days, probably in their early versions, somewhere in 2001-2002. But, the problem is that now we’re in 2010, and they hired an army of developers and math/algorithms doctors. So, they probably still count the keywords, but they must have a lot more methods that enable them to assess the quality of the page and to categorise the content. One obvious thing, they must be doing is to treat the HTML tags of the page differently. For example, a text that appears in an H1 tag, means a lot more than just a little font at the bottom of the screen. Same goes to the title tag, which appears at the top of the browser window, which SEOs noticed is very influential on the categorisation of the page.
Thus, it makes a lot more sense to use a weighted keyword density, that would not only count the number of times each keyword appears, but also take into consideration the html where that keyword was found. This is exactly the new feature that was added to SheerSEO’s keyword density screen. It shows up in the same screen as the obvious keyword density appears in. Here is a screenshot for the weighted keyword density of our home page:
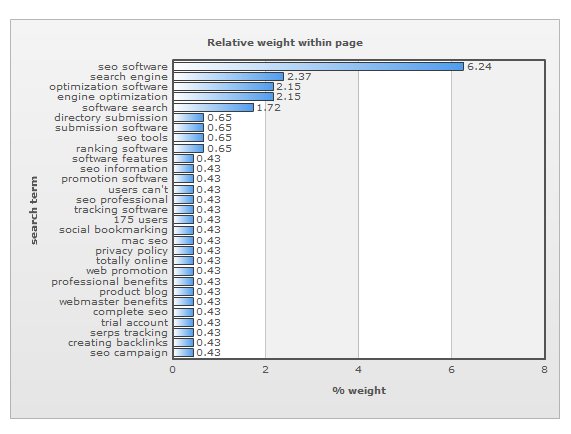
The weight that is used per tag is:
The weights are of course debatable, but this is a much improved way to see how search engines are looking at our pages. This is still not even close to all the algorithms that Google have in order to analyse a web page, but this is a big step forward. Hope you all like the new feature and find it useful.
Leave a Comment
[…] I want to introduce a new feature, which is aimed to help in our on page SEO efforts. It is an advanced way to analyze how well our page is optimized for a certain keyword. So first, let’s explain the logic behind this. We want to optimize the content of a page for a certain keyword. First thing we would do is make sure that our keyword is present in the page. If we want to be more precise about that, we would analyze the keyword density, or even better, make sure the relative weight of that keyword within… Read more »